 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConMAE: Contour Guided MAE for Unsupervised Vehicle Re-Identification
Feb 11, 2023Vehicle re-identification is a cross-view search task by matching the same target vehicle from different perspectives. It serves an important role in road-vehicle collaboration and intelligent road control. With the large-scale and dynamic road environment, the paradigm of supervised vehicle re-identification shows limited scalability because of the heavy reliance on large-scale annotated datasets. Therefore, the unsupervised vehicle re-identification with stronger cross-scene generalization ability has attracted more attention. Considering that Masked Autoencoder (MAE) has shown excellent performance in self-supervised learning, this work designs a Contour Guided Masked Autoencoder for Unsupervised Vehicle Re-Identification (ConMAE), which is inspired by extracting the informative contour clue to highlight the key regions for cross-view correlation. ConMAE is implemented by preserving the image blocks with contour pixels and randomly masking the blocks with smooth textures. In addition, to improve the quality of pseudo labels of vehicles for unsupervised re-identification, we design a label softening strategy and adaptively update the label with the increase of training steps. We carry out experiments on VeRi-776 and VehicleID datasets, and a significant performance improvement is obtained by the comparison with the state-of-the-art unsupervised vehicle re-identification methods. The code is available on the website of https://github.com/2020132075/ConMAE.
DCDLearn: Multi-order Deep Cross-distance Learning for Vehicle Re-Identification
Mar 28, 2020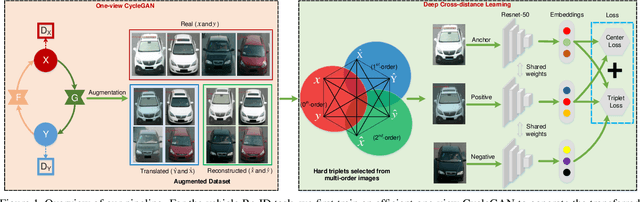

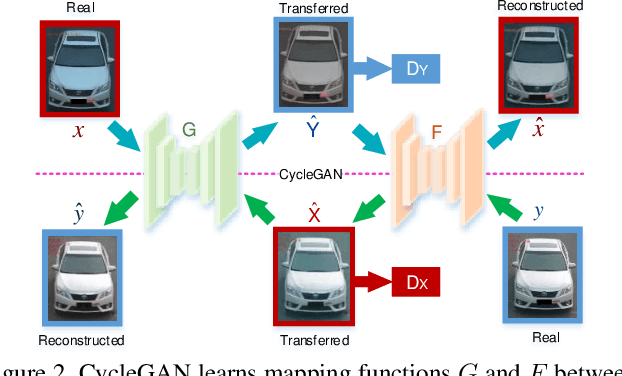
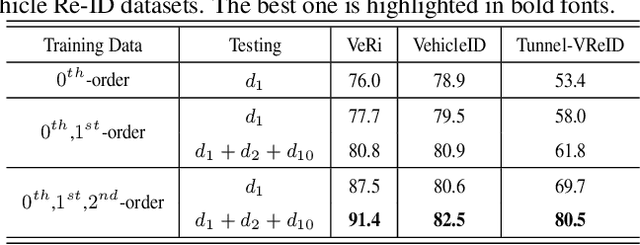
Vehicle re-identification (Re-ID) has become a popular research topic owing to its practicability in intelligent transportation systems. Vehicle Re-ID suffers the numerous challenges caused by drastic variation in illumination, occlusions, background, resolutions, viewing angles, and so on. To address it, this paper formulates a multi-order deep cross-distance learning (\textbf{DCDLearn}) model for vehicle re-identification, where an efficient one-view CycleGAN model is developed to alleviate exhaustive and enumerative cross-camera matching problem in previous works and smooth the domain discrepancy of cross cameras. Specially, we treat the transferred images and the reconstructed images generated by one-view CycleGAN as multi-order augmented data for deep cross-distance learning, where the cross distances of multi-order image set with distinct identities are learned by optimizing an objective function with multi-order augmented triplet loss and center loss to achieve the camera-invariance and identity-consistency. Extensive experiments on three vehicle Re-ID datasets demonstrate that the proposed method achieves significant improvement over the state-of-the-arts, especially for the small scale dataset.